Announcing Bytebase. Open source, web-based, zero-config, dependency-free database schema change and version control tool for Developer and DBA

After 6 months of intense development and over 2,000 commits, Bytebase version 0.1.0 finally arrives. The code is open sourced at https://github.com/bytebase/bytebase using Apache 2.0.
What is Bytebase
Bytebase is a tool for database schema change and version control, its main audience are Developers and DBAs.
Database schema migrations (aka database migrations), like code changes, are one of the routine tasks for developing applications. Although schema changes are not as frequent as code changes, they are much more dangerous. Since the data is stateful, unlike the fast code rollback, the database rollback is much more complicated. Besides database changes, network changes are also dangerous and can cause large-scale service failures. While network configurations are usually stateless, so rollback and recovery are also faster.
Thus, database changes are usually the most likely ones causing long-lasting large-scale service outages. And in the extreme case, can even bankrupt the entire business.
Since this operation is so critical and impactful, there must be many tools to solve this problem? Yes, but the reality is although the database industry has more than 40 years history. DevOps, Database CI and even Database-as-Code have been hovering around for many years. There is still no industry benchmark solution handling this task, like GitLab to code hosting, Prometheus to service monitoring.
Why we build Bytebase
Put simply, it's to answer the previous question
We want to make Bytebase the industry benchmark solution for managing database schema change.
Let's first evaluate the existing solutions first, roughly divided into 3 categories:
- Tools been around for a long time
Many teams have already adopted tools like Flyway, Liquibase in their development workflow. These tools have already built a large customer base and a thriving community. They also have a solid schema change core and stood the test of time. But, these products are all more than 10 years old, and the tech stacks used are sort of dated. For example, Flyway and Liquibase are both based in Java. Nowadays, database changes are usually used as a step in CI, and the step is often executed in a separate container. To run a Flyway/Liquibase command, one must first download a JVM or use an image containing JVM. Also, they are thin on the frontend with no or basic functionalities. Another concern is they support everything from commercial to open source databases, regardless of XML or SQL migration format. This does carry weight over the years.
- Homegrown tools
Usually when the dev group reaches ~50 people, a dedicated DBA must be summoned. And for a typical middle-sized to large company, the ratio of DBAs to Developers is between 1:150 to 1:400. To improve serving bandwidth, DBAs have to rely on tools. Starting from the most basic SQL review ticket, DBAs often would roll their own by using Python + Django. These tools are often stacked up bit by bit, starting with SQL review ticket, then cron inspector, and then monitoring, backup/restore, approval workflow etc, and finally we get a classic internal company system, like this:
 By Manu Cornet, https://goomics.net/106/
By Manu Cornet, https://goomics.net/106/
- Homegrown to open source tools
Some mindful engineers have open sourced their homegrown tools. A few have gained thousands of GitHub Stars, and been deployed in middle to large companies. These tools did provide great value. At least DBAs on longer need to reinvent wheels, especially those are not the wheels they are good at/enjoy building. But frankly speaking, from the underlying data model design all the way up to UI/UX, these open source tools are still quite far from the industry benchmark standard.
And we ask ourselves:
- What's the GitLab for database instead of for code?
- What's the Figma for DBAs instead of for designers?
- What's the Terraform for Database-as-Code instead of for Infrastructure-as-Code?
The current industry does not have a good answer yet. Before starting Bytebase, we used to be application developer, database kernel developer, DBA ourselves and have also managed the DevTools, DBA and even collaboration tool group in world's leading technology companies (Google and Ant Group). Thus we happen to have all the required skills to build such a tool.
How we build Bytebase
Since this is a launch post, we will cover some design aspects, more to be covered in separate posts.
Data modeling
Data modeling is always the center piece of the software, it's the one determining the celling of the software and is very hard to change after launch. Even being veterans in the database domain, we have spent tremendous time to make the data modeling right. Below is Bytebase's essence, its v1 data model:
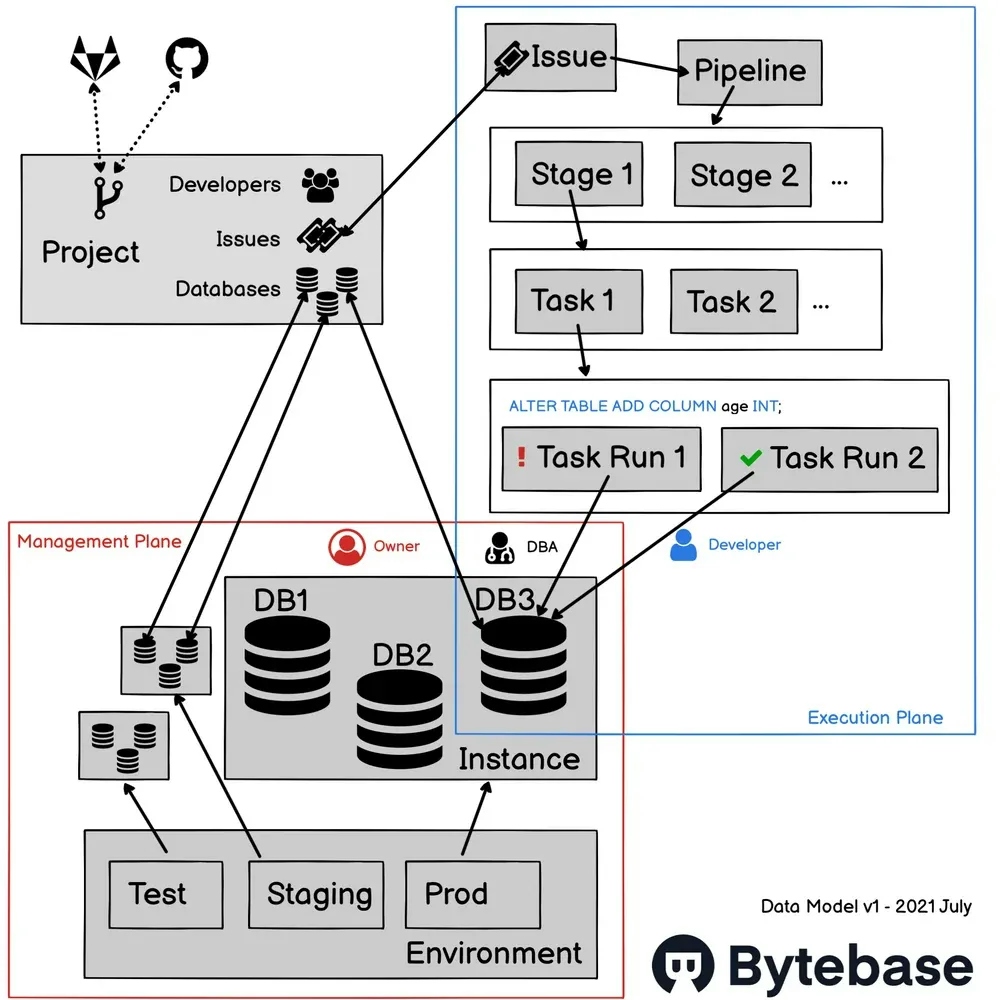
This is actually the 3rd iteration, and every iteration causes a significant refactoring. As an example, the upper right is to model the execution pipeline, Bytebase has studied all mainstream pipeline design and came up with a solution:
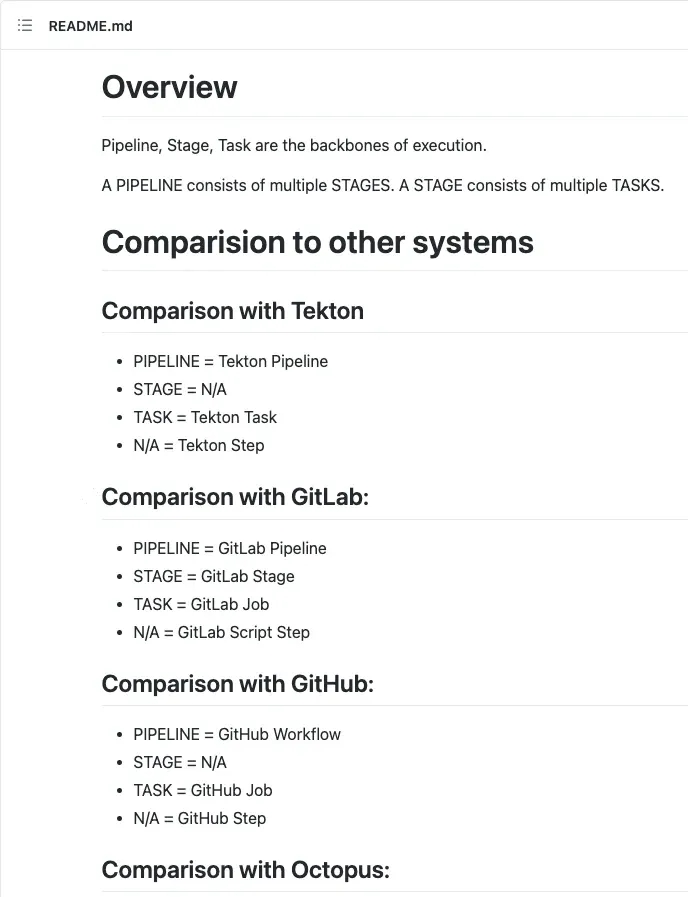
For those interested, please check our design notes: https://github.com/bytebase/bytebase/tree/main/frontend/src/types/pipeline#readme
UI and UX
To be honest, we lack the design skills to craft Bytebase to the level of the tools we aspire to like Figma, Notion, Linear. So our bottom line is to make it easy to use with a decent looking frontend. Looking at Bytebase's architecture graph:
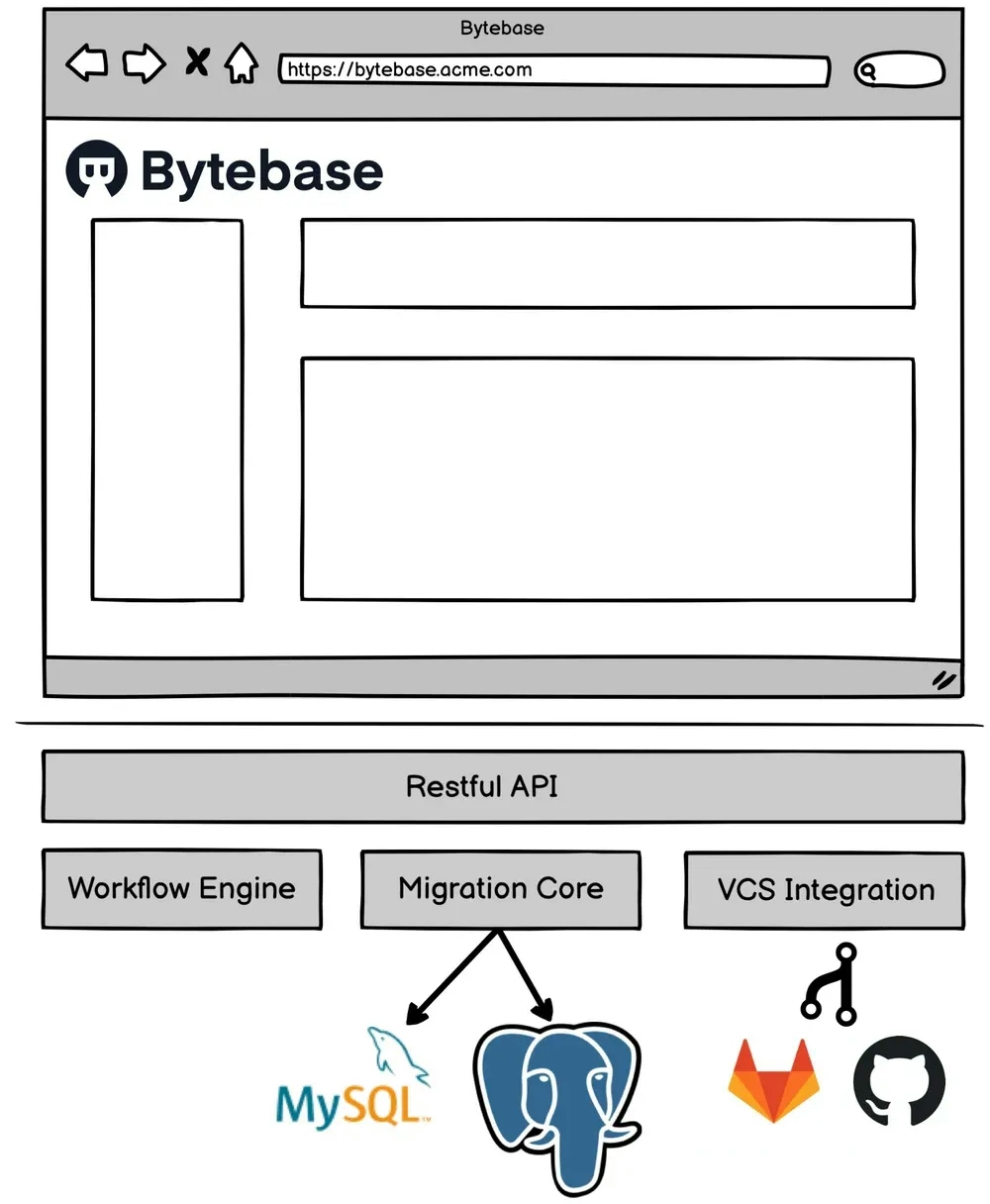
We deliberately put a large browser here to suggest the Bytebase console is a very critical piece of the product. Indeed, the frontend work takes 2/3 ~ 3/4 of the development time so far. And among those work, we spend most effort to polish the most frequently accessed UI - issue detail view.
Issue detail view
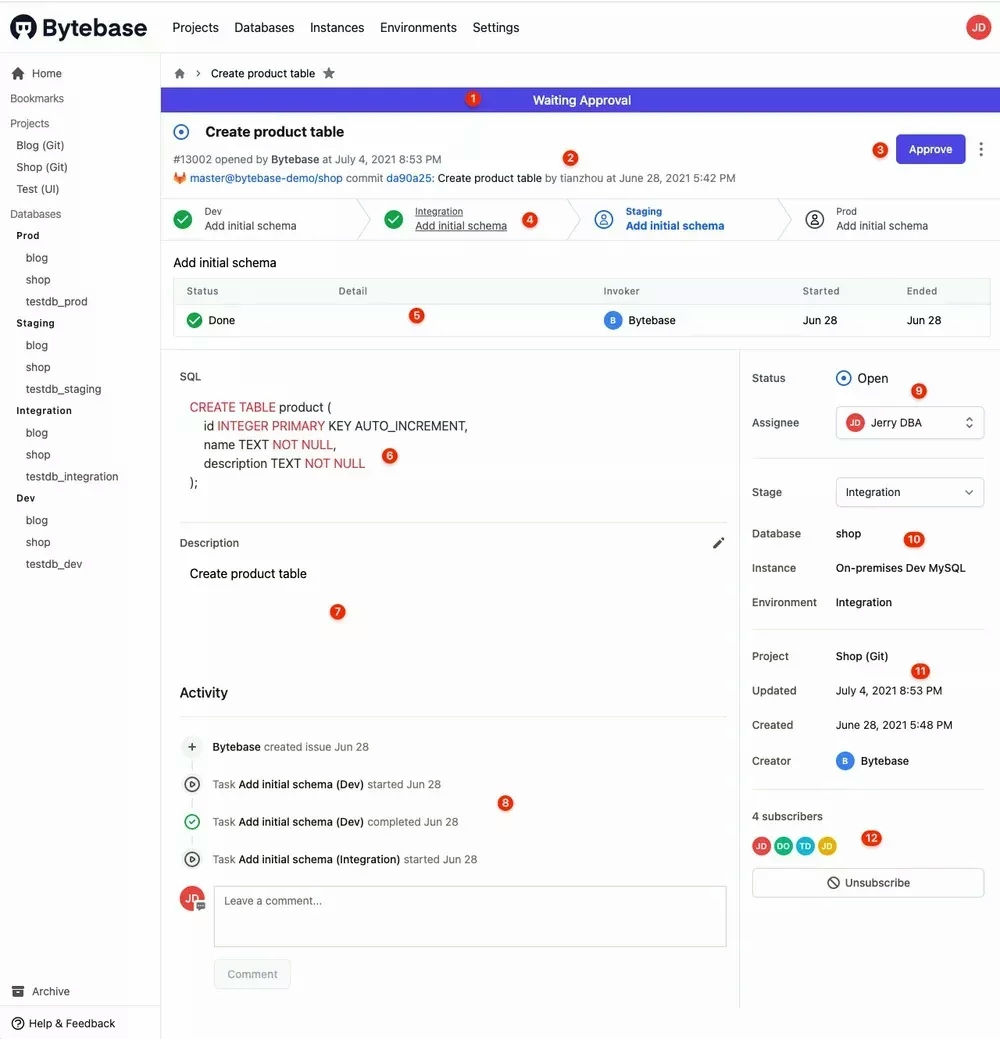
The number shows each sub-component of the issue detail view, let's take another look
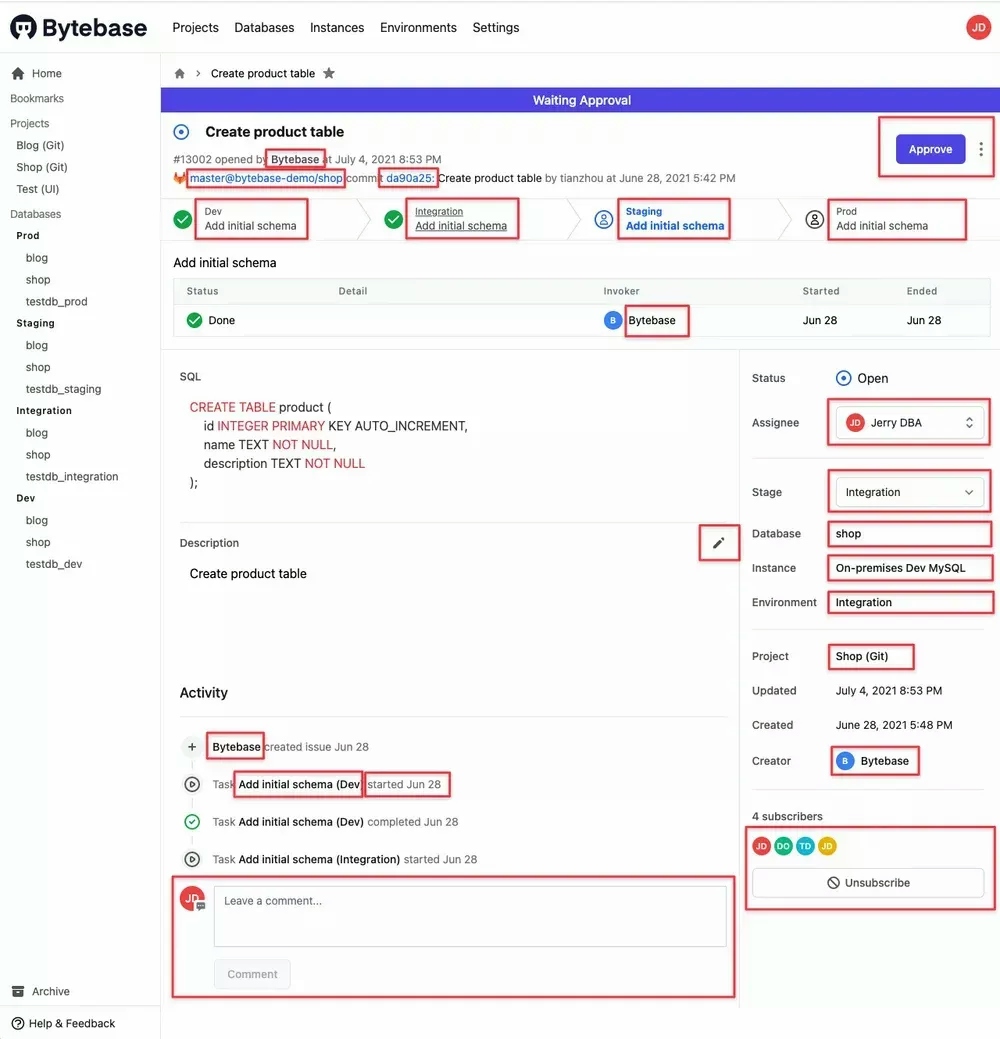
Each square shows an interactive area. Issue is the rendezvous, and we try to add link to every related object if possible.
Slug design
Next let's talk about link, and in particular the slug part.
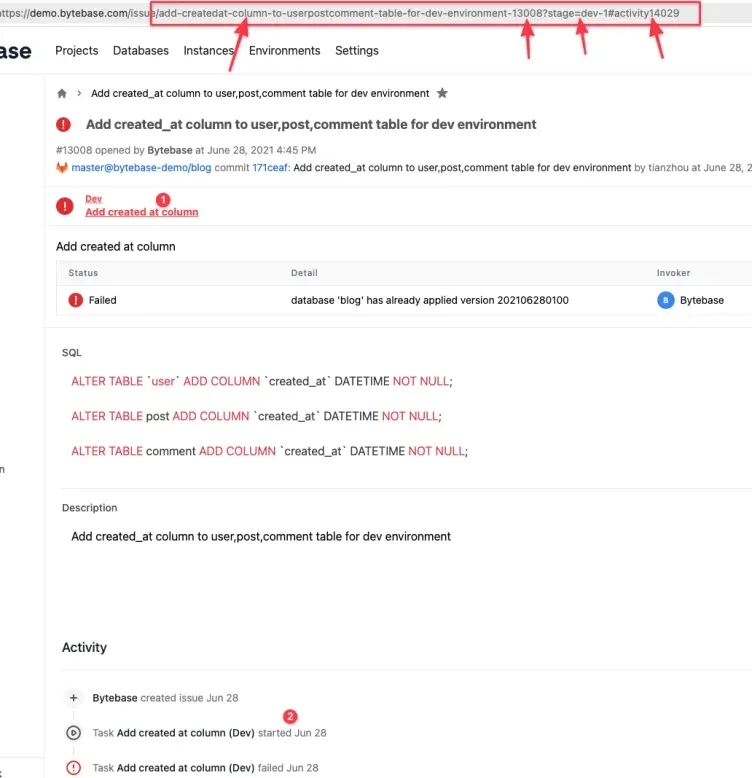
The URL is reached by first clicking the stage progress bar, followed by clicking the 2nd activity. This slug consists of 4 parts:
- add-createdat-column-to-userpostcomment-table-for-dev-environment, the issue name.
- 13008, the issue ID and the key identifying the issue.
- ?stage=dev-1, query parameter, used to locate the stage, an issue can contain many stages and different stage can show different content.
- #activity14029, anchor used to locate the exact comment position.
With this, user can learn the name, stage by skimming the URL usually seen in the doc, chat conversation. Also, by clicking the URL, user will navigate to the exact same place as the URL producer. All Bytebase pages have adopted this practice. BTW, you may notice we use auto increment integer as the issue ID instead of UUID, there are some tradeoffs involved. We will leave the discussion to a separate post.
Developer Experience
Since Bytebase chooses open source, we do want to make it more accessible to the developers. So in the very beginning, we set a design goal for Bytebase:
Zero config, start with a single command within 10 seconds.
Bytebase achieves these by:
- Use Golang as the backend, Golang is statically linked and requires no external dependency.
- Use the embedding feature introduced in Go 1.16 to package the frontend files.
- Use SQLite instead of the typical MySQL/PostgreSQL to store the data (this will be further discussed in a separate post).
The end result is the developer can just execute ./bytebase to start the entire Bytebase app. In fact, it usually takes less than 1 second from start to function.
ASCII Banner
When startup process completes, the console will print out the Bytebase ASCII banner:
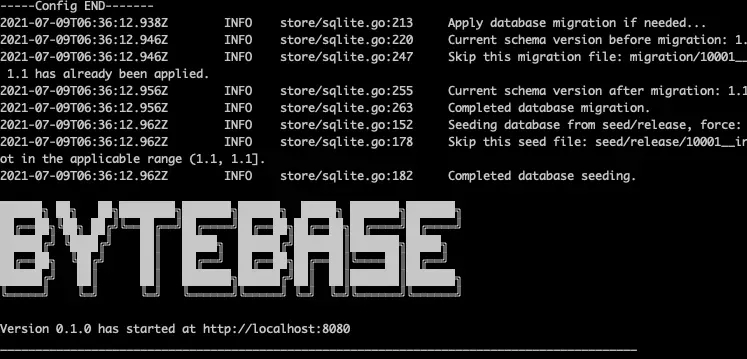
First, this is for branding purpose. But more importantly, this is to allow user to easily identify the application status. Similarly, if Bytebase stops normally, it will print out the Bye ASCII banner:
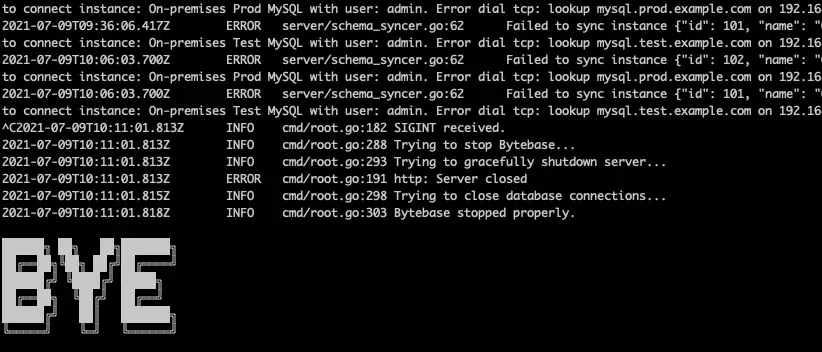
Both helps user to locate the Bytebase start/stop point among the abundant log entries.
Let the product speak
Bytebase has built-in demo and read-only mode enabled by the respective --demo, --readonly flag. In fact, demo.bytebase.com is running with both --demo and --readonly. Bytebase is a tool built for database professionals with its own design philosophy. Even for those veterans, there is a learning curve. The demo mode helps the new user to skip the cold start phase, and can jump directly to play with the core feature set. As to the read-only mode, it was originally developed for demo.bytebase.com. We want to have a clean data to show each visitor the desired demo state, and to achieve this, we need to ensure the state is immutable, and won't be messed up by the previous visitor. Moreover, since the state is immutable, we can reference the specific demo.bytebase.com page from our doc site docs.bytebase.com as the supplement live example. Later on, Bytebase can also leverage the read-only mode to develop enterprise-grade features like maintenance window and deployment freeze.
Tool not Platform (yet)
Right before the launch, we made a minor change during the last thorough code review
Tool not Platform (yet)
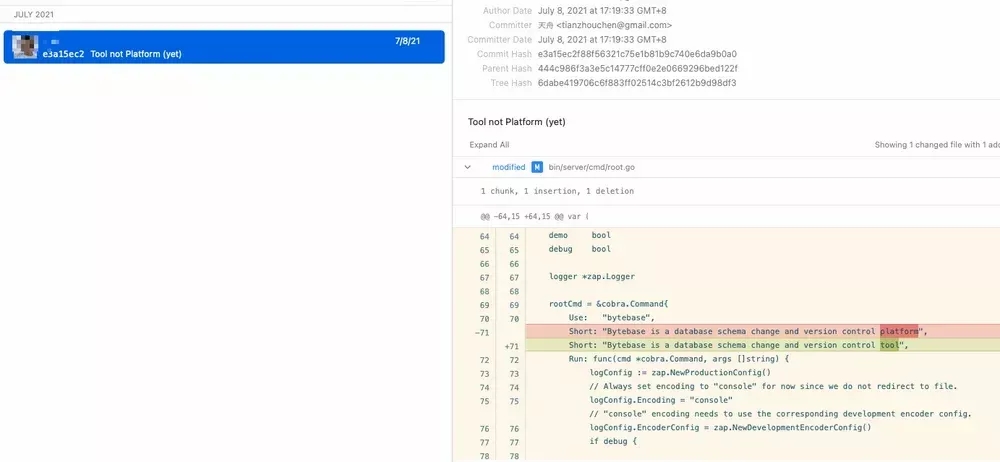
It has taken a lot of effort to bring Bytebase to the public. Yet, there is a lot of work ahead. We don't have any previous experience to run an open source community, neither do we have any marketing experience. The chosen tech stack and the data model still needs to stand the test of time. All in all, we still need to be pragmatic and focused on building a solid tool first.
Conclude
It's already a quite long post and thanks for following us thus far. You can visit https://github.com/bytebase/bytebase to check out our project. If you happen to be a DBA or a developer looking for a database schema change management tool, give Bytebase a try and let us know what you think. Feedback appreciated.
Go back to build 🚀🚀🚀


